Proceso de diseño
La tutorización con inteligencia artificial figuraba en la propuesta del proyecto SOCIA como la innovación central del SOC educativo. Sin embargo, no estaba ni definida ni desarrollada, así que era un problema a resolver. Esta página cuenta cómo lo solventamos, qué descartamos por el camino y por qué la solución final que proponemos tiene un diseño basado en tres aplicaciones independientes (MENTORA, SOCIA y el panel de control).
Los límites que nos impusimos
Sección titulada «Los límites que nos impusimos»Mientras se desarrollaba el proyecto, conforme hacíamos pruebas, fuimos imponiéndonos restricciones importantes a la hora de incorporar IA en la formación en gestión de incidentes que nos debía habilitar SOCIA.
La primera, el coste. Un SOC educativo se usa todo el curso y por muchos grupos a la vez. Una tutorización que dependiera de un modelo con un coste alto por cada pregunta no era viable a medio plazo, ni para nosotros ni para los centros que lo adoptasen más adelante.
La segunda, la integración pedagógica. La IA tenía que aportar algo al aprendizaje en el momento exacto en que el estudiante la usa, no estorbar ni convertirse en un atajo para saltarse el ejercicio. Además, cuanta menos fricción introdujera, mejor.
La tercera, los modelos abiertos. Queríamos poder funcionar con modelos open source y no quedar atados a una empresa concreta. Eso protege al proyecto a largo plazo y permite a cada centro decidir dónde aloja la inteligencia. Así, teniendo la suficiente capacidad de procesamiento, podría incluso ejecutarse en la misma infraestructura del centro educativo.
La cuarta, pensar muy bien la interacción del alumnado con el sistema. En experiencias anteriores con metodologías basadas en IA habíamos comprobado que en muchas ocasiones les poníamos un chat por delante y no sabían por dónde empezar, ni qué es lo que debían escribir. Demasiada libertad en la interacción llevaba a obstaculizar un uso fluido de la aplicación.
Con estas cuatro limitaciones encima de la mesa, varias soluciones que parecían razonables fueron descartándose. Eso no quita que los prototipos no fueran imprescindibles para poder llegar a plantear la solución que tenemos actualmente.
Primer intento: Cybermaster sobre Security Onion
Sección titulada «Primer intento: Cybermaster sobre Security Onion»El primer acercamiento llegó durante el curso 2024-2025. Dos alumnos del Curso de Especialización en Inteligencia Artificial y Big Data del IES Rafael Alberti, que habían cursado el año anterior la Especialización en Ciberseguridad en Entornos de las Tecnologías de la Información, decidieron enfrentarse al reto de hacer las primeras pruebas para SOCIA. La infraestructura del SOC todavía no estaba decidida, así que partieron de Security Onion, una aplicación todo en uno open source para gestionar un SOC, y construyeron un chatbot que hablaba con su API mediante el uso de tools personalizadas. El estudiante podía consultar información, crear algunos casos y otras funcionalidades similares. Lo llamaron Cybermaster.
Cybermaster sirvió como prueba de concepto. Demostró que un agente sobre la API de un SIEM era técnicamente posible y nos permitió empezar a entender los problemas de interacción que podían surgir con un chatbot.

Segundo intento: SOCdash, un MCP sobre la infraestructura
Sección titulada «Segundo intento: SOCdash, un MCP sobre la infraestructura»Cuando la arquitectura del SOC quedó definida, empezamos a pensar dónde tenía sentido alojar al asistente. TheHive parecía el sitio natural: es donde la persona que gestiona el caso pasa la mayor parte del tiempo y la aplicación en la que toma las decisiones importantes. Empezamos a desarrollar un servidor MCP con tools propias, interactuando con la API de OPNsense, Wazuh y otras plataformas del stack para leer el estado y aplicar medidas. Lo llamamos SOCdash.
Sobre el papel funcionaba. En la práctica acumuló problemas hasta hacerse inviable.

El primero, el coste real en tokens. Para que el agente respondiera con sentido necesitaba recopilar mucho contexto antes de responder: qué había hecho ya el estudiante, qué le faltaba, qué decía el caso. Cada interacción se traducía en varias llamadas a tools, mucho texto entrando y saliendo, y un tiempo de espera notable. Una cosa interesante que probamos para solventar esto, fue implementar en las mismas tools un output resumido cacheado. Es decir, si por ejemplo el agente hacía una llamada para obtener los últimos logs de Graylog, en lugar de obtener los logs en bruto, la misma tool con un prompt personalizado los enviaba a otro LLM configurado para que los interpretara de forma resumida. Así, el contexto del agente principal se sobrecargaba mucho menos. Además, esa respuesta se cacheaba, de forma que si el agente de otro estudiante hacía la misma consulta con los mismos logs, no se volvían a procesar y se obtenía directamente el resumen. Esto mejoraba los costes y la velocidad de respuesta, aunque no lo suficiente como para satisfacernos.
El segundo, la ambigüedad. Reconstruir el estado del ejercicio a partir de lo que se podía leer de las distintas APIs era frágil. El agente acertaba a veces y otras no, y la falta de un terreno firme (grounding, si usamos el anglicismo) convertía cada interacción en una incertidumbre demasiado grande para nuestros criterios de calidad.
El tercero, el del chat por delante. El asistente estaba solo en TheHive, así que era bastante incómodo para el estudiante volver a esta pestaña cuando quería hacer alguna consulta y estaba en otra aplicación. Además, volvíamos al problema ya conocido: muchos estudiantes no sabían qué preguntar ni cómo formularlo. A eso había que sumarle, claro, los riesgos habituales de cualquier chatbot abierto al usuario, prompt injection incluido.
El cuarto, el trabajo del docente. Diseñar casos nuevos sobre esa base resultaba bastante complicado. Cualquier cambio implicaba revisar prompts, tools y permisos.
Las conclusiones de este intento no fueron buenas. Pero nos sirvió para darnos cuenta de que el problema no estaba en los modelos de lenguaje, sino en el diseño que estábamos planteando. Así que tocó dar un paso atrás.
Vuelta a empezar
Sección titulada «Vuelta a empezar»Pensando en mejores opciones, apareció una idea más sencilla. Todas las aplicaciones del SOC se acceden desde el navegador. Si el asistente se instalaba también ahí, en forma de extensión web, podía acompañar al estudiante por TheHive, Graylog, Malcolm y donde hiciera falta, sin necesidad de instalar ni modificar nada en cada plataforma.
Y, a la vez, decidimos quitar el chat del medio. En lugar de una caja de texto donde el alumno tuviera que escribir, solo mostraríamos un botón. Al pulsarlo, devolvería una pista contextualizada, en una o dos frases, en función de lo que el estudiante ha hecho hasta ese momento y de lo que le queda por hacer. No encontramos ninguna razón por la que el alumnado necesitara más que eso a la hora de enfrentarse a un caso.
Ese cambio resolvía varios problemas a la vez. El alumnado no tiene que pensar qué escribir, así que no se bloquea. Al controlar nosotros el input desaparecen el prompt injection y la mayor parte del coste imprevisible. El output, al ser una pista corta, es barato y rápido. Solo quedaba una pregunta por resolver: ¿Cómo construimos el contexto que el modelo necesita para dar una pista útil en cada momento?
Cómo resolvimos el seguimiento del caso
Sección titulada «Cómo resolvimos el seguimiento del caso»Necesitábamos descomponer cada caso en diferentes pasos y tener algún tipo de control sobre lo que había hecho el estudiante y lo que no. Era fundamental para poder hacer un seguimiento de cara a evaluar su desempeño y, también, proporcionar el contexto necesario al asistente de IA para darle pistas con sentido. Consideramos diseñar y usar IA para el propio seguimiento, pero aumentaba mucho el coste y generaba muchos problemas relativos al indeterminismo. En definitiva, perdíamos mucho control al respecto.
La solución que encontramos fue describir cada caso de forma programática. Un JSON en un formato determinado que indicara los pasos del ejercicio y las condiciones que deben cumplirse en el navegador para considerar cada paso superado: presencia de determinados elementos en el DOM, valores concretos en formularios o ciertas peticiones de red. La extensión monitoriza el navegador y valida pasos contra esas condiciones, sin necesidad de realizar ninguna llamada a un modelo de IA.
Cuando el estudiante pulsa el botón de pedir pista, la extensión construye un prompt con lo que ha hecho y lo que le queda para completar el caso, luego se lo envía al modelo de lenguaje con las descripciones adecuadas, que solo entonces entra en juego. Así nació la extensión SOCIA, el único componente que necesita instalar el alumnado.
Al terminar el caso, se envía al modelo un prompt con información sobre las acciones realizadas por el estudiante: pasos resueltos, pistas pedidas, tiempo invertido y una calificación calculada. Así, tiene toda la información necesaria para redactar una retroalimentación de calidad, que se entrega en forma de documento PDF.
Cómo resolvimos la creación de casos
Sección titulada «Cómo resolvimos la creación de casos»SOCIA funcionaba, pero apareció un problema bastante importante. Crear el JSON de un caso resultaba muy complicado para el profesorado, especialmente cuando los ejercicios son más complejos. Si queríamos que otros docentes adoptaran la plataforma y se animaran a elaborar nuevos casos, había que facilitarles mucho más el trabajo.
Entonces surgió la idea de MENTORA. Es una extensión que el profesor activa antes de resolver un caso. Mientras lo realiza y lo explica en voz alta, MENTORA registra mucha información del navegador: capturas de pantalla, acciones del usuario, vídeo de la sesión y transcripción de la voz. Al terminar, lo comprime todo en un ZIP.
Creamos una skill para agentes (Claude Code, Codex, OpenCode o cualquier herramienta equivalente). El agente, siguiendo las indicaciones de dicha skill, genera automáticamente el JSON del caso. Así, el docente solamente tiene que hacer una revisión rápida y una prueba en SOCIA para validar que todo está listo para ser utilizado por el alumnado.
Tuvimos una idea para una segunda skill: a partir del ZIP, selecciona las capturas relevantes y, apoyándose en la explicación verbal del profesor, elabora una guía paso a paso del caso. Así, la podría utilizar el profesorado como apoyo en clase y también puede entregarse al alumnado como material de estudio.
Casi sin darnos cuenta, acabamos teniendo entre manos un sistema de documentación y creación de contenido didáctico automático para nuestro proyecto.
Cómo resolvimos la gestión de casos en el aula
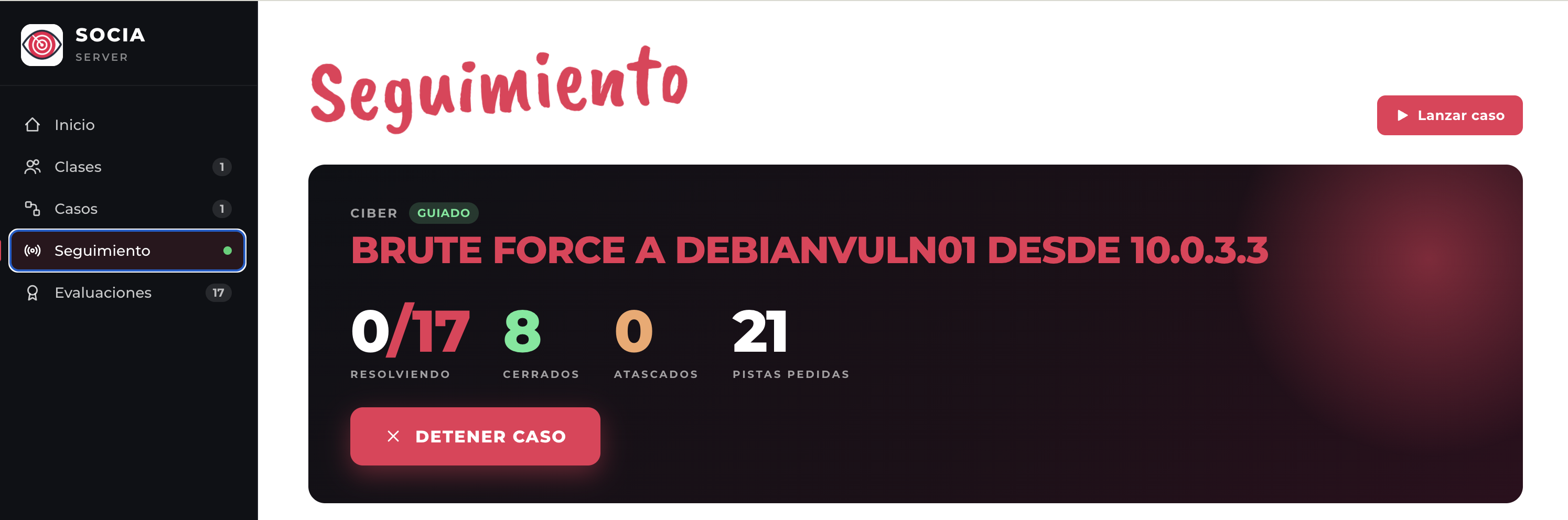
Sección titulada «Cómo resolvimos la gestión de casos en el aula»En este punto teníamos un sistema preparado para crear casos y ponerlos en práctica. Pero aún existía bastante fricción en la gestión del aula. El docente tenía que enviarle el JSON al estudiante (que podía abrir y recibir bastantes pistas con su lectura) y después tenía que enviar de vuelta el PDF con la evaluación que generaba.
Para solventar este problema, construimos el panel web de SOCIA (SOCIA Server). Desde el mismo, el docente puede crear clases, agregar y configurar casos, desplegarlos a las extensiones SOCIA de cada estudiante, monitorizar el avance de los mismos en tiempo real y recibir toda la información de su desempeño. El complemento perfecto que nos permitió llevar el sistema desarrollado al aula.
La solución que proponemos
Sección titulada «La solución que proponemos»La idea inicial ha cambiado bastante respecto a lo que imaginábamos al realizar la solicitud del proyecto. Empezamos pensando en un asistente de IA y terminamos con tres componentes que se apoyan entre sí: MENTORA convierte la explicación del docente en un caso publicable, SOCIA acompaña al alumnado durante la resolución proporcionando pistas (si son necesarias) y retroalimentación, y el panel de control orquesta la distribución y el seguimiento.
Lo importante es que cada componente apareció para resolver un problema concreto. Aún así, lo que tenemos hoy no es un diseño cerrado. A partir de aquí compartimos lo que hemos hecho con la comunidad y estamos abiertos a debates y modificaciones sobre la mejor opción para la continuidad del proyecto.
La bienvenida ventaja colateral
Sección titulada «La bienvenida ventaja colateral»Mientras desarrollábamos todo esto nos dimos cuenta de algo que ya se puede intuir por la explicación del diseño: el mecanismo que hace funcionar a MENTORA y SOCIA no tiene nada específico de ciberseguridad o las aplicaciones del SOC, más allá de que son aplicaciones web. MENTORA graba a alguien haciendo algo en un navegador y genera un workflow a partir de esa grabación. SOCIA carga ese workflow, observa las peticiones de red del estudiante, las compara con las acciones esperadas y ofrece pistas cuando se atasca. Este ciclo sirve para cualquier procedimiento que ocurra en la web: formación en ERPs, plataformas sanitarias, administración electrónica, contabilidad, o cualquier SaaS con el que se trabaje desde el navegador.
Somos conscientes de que lo que tenemos realmente es, en el fondo, una versión inicial de un motor de evaluación procedimental que hoy forma parte de este proyecto de ciberseguridad educativa. Elegimos mantenerlo dentro de SOCIA en lugar de independizarlo de forma genérica porque preferimos que madure en un contexto real con estudiantes y docentes antes de plantearnos abstraerlo. Además, la arquitectura para quien quiera adaptarlo ya lo permite sin grandes cambios; sería cuestión de modificar ligeramente algunas instrucciones en la skill y el prompt del modelo de lenguaje.
Si en el futuro el proyecto genera interés fuera de la ciberseguridad, estudiaremos cómo separar el motor genérico de la vertical educativa de SOC de la mejor forma posible, sin dejar el proyecto SOCIA de lado. Pero eso será una decisión que tomemos cuando tenga sentido hacerlo. Mientras tanto, preferimos dejar constancia de que vimos el potencial y que decidimos, deliberadamente, priorizar la profundidad en un dominio concreto frente a la generalización.